4.2. Topic Modeling Future Stories For Europe
4.2.2. Document Preprocessing
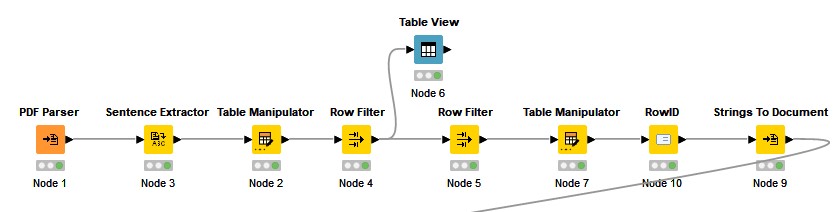
So, the workflow starts with the PDF Parser node, which returns the book in computer-readable format. The top line of the workflow can be referred to as the document preprocessing section, which is pictured below. In it, we will put nodes that format our documents into the format we want. Here, we make the first choice based on the granularity we want of the separate items in our sample. The example workflow makes use of a Sentence Extractor node, meaning that we will engage with our sample at a sentence level. The third node is a Table Manipulator, which allows us to interact with the table populated with the sentences from our PDFs. We can use this manipulator to remove columns that are not relevant to our process or as a quick way to check on the output of the sentence extractor. This is then followed by two Row Filter nodes.
The row filters are there so that we can cut content from the beginning and end of our sample. The reason that we want to do this is that the first pages and the last pages do not contain text that is part of our stories, but rather publication information, index and editorial materials. Since the row filter will cut one segment of the table, we need two in order to get both the initial and final non-content pages. We kept the material for the "Stories from 2050" between row 29 and 1603. When you decide to do this with your materials, you can use the table view node to easily inspect the materials. In the example, the table manipulator provides enough rows at the beginning of the table for the first filter to be configured. Still, a table viewer was added in order to be able to see the final rows.
We then use the Row ID node to add an ID for each of our rows into the table. At this point, this is basically a column into which the current row index number is copied. We will later use this to identify which data belongs to which row. After having added the IDs, we pass our data on to a Strings to Document node, which turns each extracted sentence into its own document. Here, it is important that we configure the Strings to Document node so that each document uses the Row ID column for its title. The reason for us turning each extracted sentence into its own document is so that we can run them through the topic model while keeping them separate. Before that, though, we will have to preprocess each document's text.