2.2. Patterns in language and text
2.2.2. Collocation networks
In order to gain further insight into the context of a query word and its collocates, we can also create collocation networks. Collocation networks are built from the query terms and their most significant collocates. These collocates are then queried for their own frequent collocates, which thus become the central nodes of their own collocate networks, and so on. By doing this, we can see the direct collocates and the network of common contexts in which they appear. This approach makes distributional semantics much easier to comprehend.
As an example, we could run queries for the verbal collocates of kinship terms, such as "husband", "wife", "daughter", "son", and so on, in a large generic corpus; the data for the image comes from the 38-billion-word EnTenTen20 corpus and the network graph was created with the open-access network analysis tool Cytoscape. By focusing on the verbs governed by kinship terms, we can examine the activities that are associated with family members in the English language. A network of the collocates can then be constructed, revealing that there are specific activities (as indicated by the association of the kinship terms and specific verbs) that are typically carried out by the parents but not the children or female members of the household but not the males, and perhaps some that are only associated with one type of family member but none of the others. In the example figure, we see that "daughter" and "son" are drawn close together, as are "mother" and "father", indicating that while there are some verbs that are shared by all four nouns, there are more similarities between the younger and older family members. The data also suggests that the verbs "kill", "fight", and "serve" are shared by fathers and sons but not mothers and daughters, while mothers and daughters share the verbs "struggle", "cry" and "sit" with each other, but not with the fathers and sons. Data-driven insights like this can serve as a starting point for a more qualitative study, which examines exactly how and why these verbs relate to specific kinship terms.
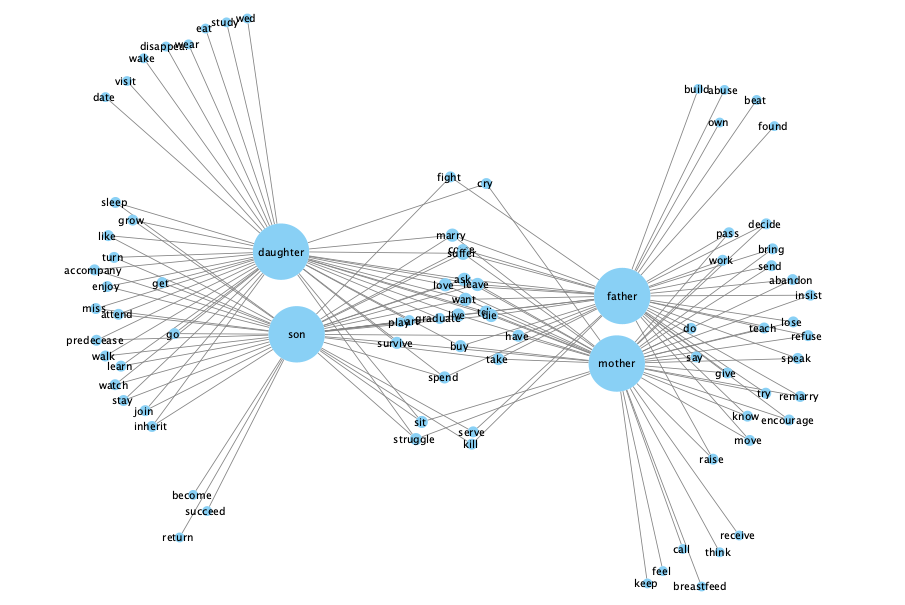
A study like this could easily be expanded by replicating the same study using corpora representing different countries or time periods, which could identify geographic, cultural or diachronic differences.
Collocation networks can also reveal differences between words, which can be particularly revealing when it comes to words that are closely associated, such as synonyms. Synonyms are likely to be used in relatively similar ways and thus share plenty of the same collocates. Still, the subtle differences in meaning may be shown by focusing on the smaller subset of collocates they do not share. Some corpus tools, such as SketchEngine, make use of collocation similarities in constructing data-driven thesauri or synonym dictionaries.
Standard corpus tools do not normally provide simple ways of visualising collocation networks. MORE HERE
For other uses of networks, consider taking a look at: